Video Compression Techniques

The Basics Of Compression
‘Compression’ is a technique that is used to convert data into a form that contains fewer bits. In the simplest terms, it is the process of reducing the image data. This process undoubtedly facilitates efficient storage and effective transmission of data. The reverse process of extracting the original data from the encoded one is called ‘decompression’ or ‘decoding’. The device that aids the encoding and decoding process are known as ‘encoder’ and ‘decoder’ respectively. A device named ‘codec’ is the combination of both, an encoder and a decoder.
Lossless And Lossy Compression
There are two basic categories of compression methods:
- Lossless compression: It refers to a class of algorithms that allow 100% recovery of original data from the compressed data. This compression is most commonly used for executable files and text, where the reconstruction of exact original data is critical and loss of any information (big or small) would be a major one. GIF is one such example that uses lossless compression methods. Only a limited amount of techniques is employed for data reduction and these compression techniques use statistical information to reduce redundancies. The two most popular algorithms that are used for lossless compression, which also offer high compression ratio, are ‘Run Length Encoding’ and ‘Huffman-Coding’.
- Lossy Compression: With this compression technique, it is not possible to extract 100% of original data from the compressed data. It is ideally used for data that contains many redundancies and is not sensitive to any kind of information loss. Images, videos and sounds are the main examples where lossy compression is truly applicable. This technique provides higher compression ratios as compared to lossless compression.

Video Compression
Why Video Compression Is Needed?
Uncompressed images and videos result into huge amount of data. For example, a High Definition Television (HDTV) has the bandwidth requirements of around 2 GB/s. Such high bandwidth requirements pose extremely high computational power for proper management and handling of data. Although we have powerful computer systems with processor power, storage, and network bandwidth at our disposal; still, these computational requirements are not economical or practical to be achieved. Fortunately, the redundancies in digital video make it suitable for compression, which can help combat the computational and bandwidth issues. But, there would always be a trade-off between data size, computational time, and quality. The more the compression ratio, the lesser is the size and the lesser the quality.
An Overview Of Different Video Compression Techniques
MPEG-1
This is the first standard of MPEG (Moving Picture Coding Experts Group) committee that was released publicly and its first part was completed in 1992. The said technique emphasizes more on the compression ratio rather than the video quality.
The main aim was to provide VHS (Video Home Systems – consumer level analog video recording) quality for audio and video at 1.5 Mbps. MPEG-1 focuses on stored interactive video applications like CD-ROMS. Using this one, the user can store up to 72 minutes of VHS quality audio and video on a single CD.
MPEG-1 can also deliver full-motion color video at a frame rate of 30fps. As audio is also associated with full motion video, this standard provides the audio compression at 64, 96, 128, and 192 kbps.
The standard also allows synchronization of audio, video, fast forward, and backward search features. Also, it achieves low computation times for encoding and decoding, which is a key feature for symmetric applications such as video telephony.
The frames, using MPEG – 1, are encoded in three different manners as explained below:
- I-Frame: Intra-coded frames are discreet frames and are coded independently of its adjacent frames.
- P-Frame: Predictive-coded frames are encoded with a prediction from its past frame, which could either be an I-frame or a P-frame. The compression ratio also improves with predictive-frames.
- B-Frame: Bi-directional-predictive-coded frames are encoded by the prediction of a past frame and the forecast of a future frame, which could either be an I-frame or a P-frame. The compression ratio turns out to be the best with this technique.
MPEG-2Â Â Â Â Â Â Â Â Â Â Â
MPEG-2, an international standard released in 1994, was developed with a goal to extend the techniques and methods of MPEG-1 in order to attain higher quality of images and videos. But, the improved video quality and larger image sizes are achieved at the expense of a slightly higher bandwidth. If the video quality is to be improved and that too at the same bit rate, then it requires much more complex equipment.
MPEG-2 is fully compatible with MPEG-1. The allowed frame rates for MPEG-2 are 25fps and 30fps, which are the same as that of MPEG-1. However, when it comes to scalability, MPEG-2 has an upper hand over MPEG-1. The user can play the same video in different frame rates and resolutions. It provides high quality digital video after compression at the rate of 2-80 Mbps.
This international compression standard also specifies the methods to multiplex numerous video, audio, and private-data streams into a single stream, which in turn supports a wide range of computing and storage applications.
The primary purpose of MPEG-2 was to support interlaced video from conventional television, but today its use has been extended to high-definition television (HDTV), cable TV (CATV), and interactive storage media (ISM). The DVD movies are also compressed using the MPEG-2 techniques. But, MPEG-2 is not designed for internet as the bandwidth requirements are too high for this purpose.
Profiles and levels were introduced in MPEG-2 to present application specific implementations.
- Profile: It defines the color resolution and the bit stream capability. Basically, profile represents subset of all the tools applicable for an application. With a higher profile, it is possible to extract a low bit stream in order to achieve a lower frame rate or resolution. The profile is presented by the X-axis on the graph.
- Level: It represents the complexity of any profile in terms of image resolution, the Luminance samples per Sec, audio and video layers, and the maximum bit-rate per profile. Levels are presented by Y-axis on the graph.
For instance, DVD & Digital TV are represented by Main Profile at Main Level (MP@ML) and the HDTV is represented by Main Profile at High Level (MP@HL).
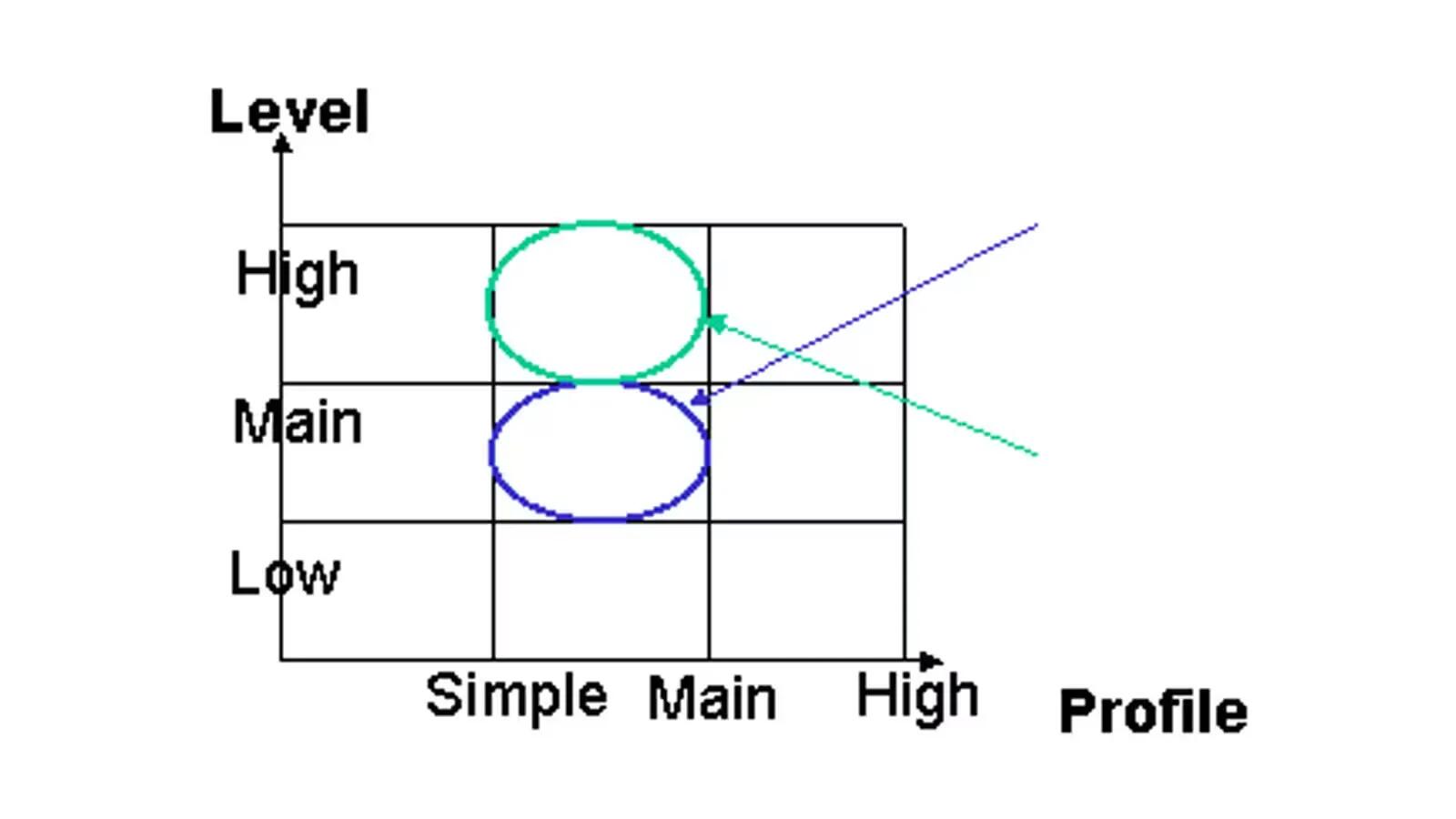
MPEG-2 Profiles (MP@ML , MP@HL)
MPEG-4
The next-generation format, MPEG-4, was released in 1998 as an inclusive superset of MPEG-1 and MPEG-2. Once again, we got an improved version that focused on supporting more applications, functionalities, and features.
MPEG-4 compression technique provided low bit rates (10kbps to 1 Mbps) with good video quality. It was designed for interactive environments such as multimedia application and video communication. The spectrum of applications supported by MPEG-4 is a lot wider than MPEG-1 and MPEG-2. For instance, it can support consumer applications on a mobile device with lower bandwidth requirements for heavy applications which require extremely high bandwidth and video quality.
The MPEG-4 format supports all frame rates, as it incorporates the frame-based coding techniques from MPEG-1 as well as MPEG-2 standards.
MPEG-4 works on either content-based manipulation or object based manipulation for better transmission of data. The aural, visual or audiovisual content in a frame is grouped into objects, which can be ‘synthetic’ (as in interactive graphics applications) or ‘natural’ (as in digital television). These objects can be accessed individually via MPEG-4 MSDL (Syntactic Description Language) and then, can be integrated to form complex objects. Further, these objects are multiplexed and synchronized to extend QoS (quality of service) while transmitting the data. These media objects can be at any place in the coordinate system.
MPEG-4 also code objects (both audio and video) at their native resolutions, supporting bit-stream editing and content-based manipulation, without the need of transcoding.
MPEG-4 enhances the precedent compression techniques with the tools that lower the bit rate on an application specific basis. These tools are, therefore, more adaptive to the specific area of usage. For instance, MPEG-4 provides better re-usability of content and a greater protection of copyrights for multimedia producers.
H.264/AVC (Advanced Video Compression)
H.264 is the latest compression technique approved by ITU-T in March 2003. The main objective for the development of the H.264 was to double the coding efficiency in comparison to any other preceding image & video coding standards that are currently being used by different applications. This new standard was expected to outperform all the earlier ones.
The challenge was to develop a technique with a lot of improvements over its previous versions and yet, with a design that is comparatively simple, practical, and economical to build applications and systems on. Besides all these changes, the next generation standard is also expected to be flexible and capable of handling a wide spectrum of applications viz. from low bit rates to high bit rate applications, from high latency to low latency, and from low resolution to high resolution images and videos.
H.264 support a number of applications with different requirements as listed below:
- Entertainment video including satellite, cable, DVD, broadcast, etc. (1 Mbps-10 Mbps)
- Telecom Services
- Streaming Services
The coding efficiency is enhanced due to the following features:
- Accuracy for Quarter Sample Motion vector
- Picture motion compensation for multiple reference
- In-the-loop de-block filtering
- 4×4 block transformation
- Enhanced entropy coding methods
- Context Adaptive Binary Arithmetic Coding
- Context- Adaptive Variable-Length Coding
- Arithmetic coding of coefficients & MVs
- Compute sum of Absolute Transformed Differences (SATD)
- Eliminates the problem of mismatch between different implementations and encoder/decoder drift.
No matter which compression standard we choose, there would always be a trade-off (less or more) between the data volume, quality and complexity. The application of a video is the ultimate deciding factor that which compression method will work best for it.
The market is always on the lookout for the techniques that proffer better quality, higher resolution, and higher frame rate with minimum possible bandwidth requirements. In the future, we may expect some standards that would combine all the best features of the existing techniques and also, overcome their shortcomings to achieve what we expect!








